In a previous post, we covered the importance of fraud models in today's financial system as well as their two main types: rules-based and algorithmic models. Now, we’ll consider the two main types of errors that fraud models make, the necessary balance between model effectiveness and mistakes, and the implications that influence which types of errors a company might prefer. Additionally, we’ll dive into aggressive and passive models and how model adjustments can lead to each of these outcomes.
Model errors: why balance is necessary
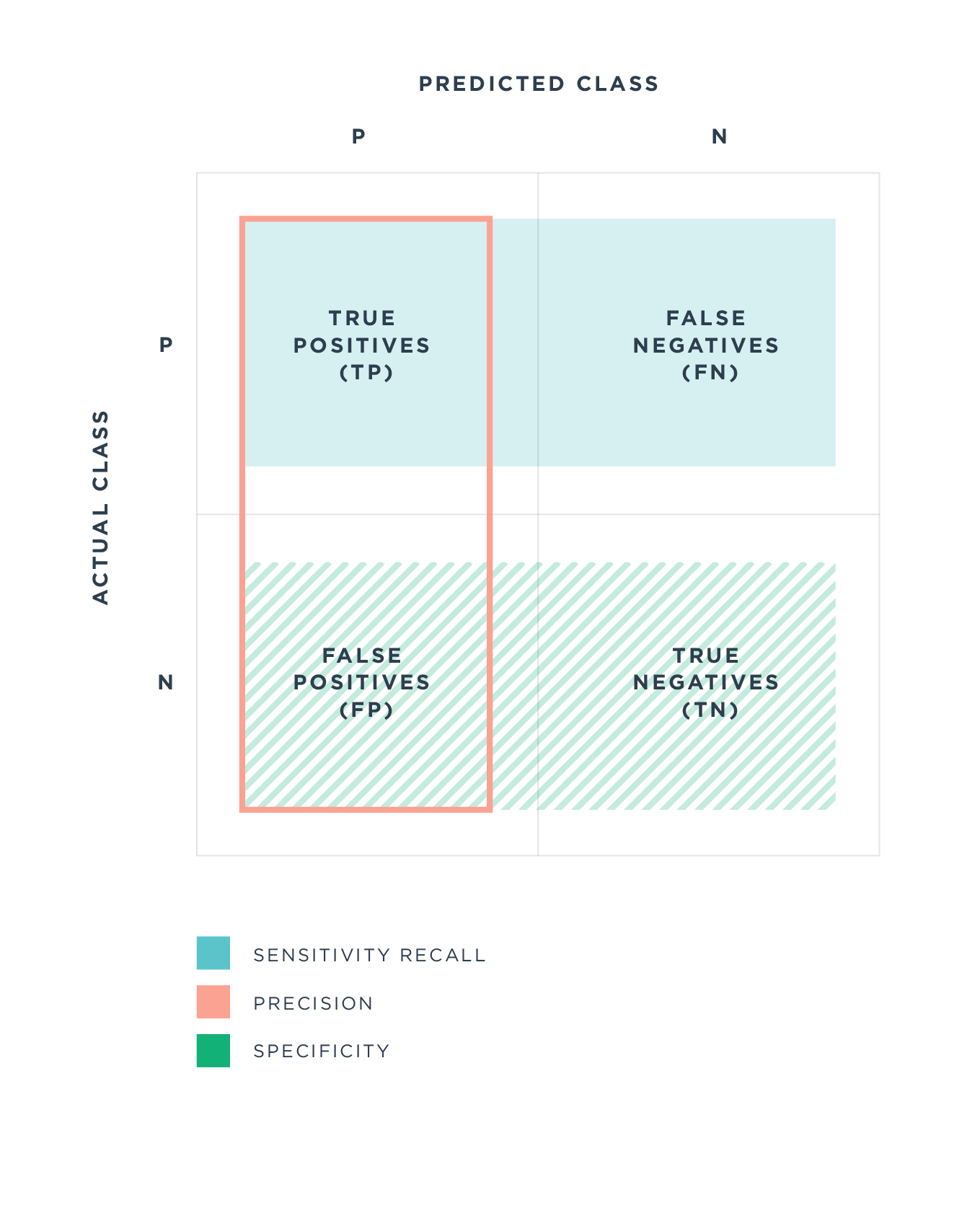
First, a word about some shortcomings: It’s important to keep in mind that, irrespective of the type of model being used, no model will ever be 100 percent accurate. In the case of fraud detection, there are two primary types of errors. False positives occur when a model incorrectly labels a legitimate transaction as fraudulent, while false negatives happen when a model mistakenly lets a fraudulent transaction through. Getting into the jargon a bit, a model's false positive rate is related to its precision, while its false negative rate is related to its recall. In general, rules-based models are more likely to produce false negatives and algorithmic models more likely to produce false positives. However, this generality is by no means definitive, and both types of models can be tuned or adjusted to favor one type of error over another.
So why not eliminate one of these types of mistakes in order to have a model that is “perfect” in at least one aspect? Let’s consider a theoretical model that labels all transactions as legitimate. Since this model never flags a transaction as fraudulent, it will never mistakenly flag a legitimate transaction as fraudulent and thus has a 0-percent false positive rate. While brilliant in this regard, it’s useless as a fraud model— it does not actually detect any fraud. Instead, any meaningful models will almost always make some mistakes of both kinds, and the right model appropriately balances the two types. In order to figure out how to do this, it is essential to understand the mistakes and how they affect a business.
False positives and their business implications
A false positive occurs when a user attempts to conduct some type of legitimate transaction that is mistakenly flagged as fraudulent by the model being used.
A harmless example of this is a card being mistakenly declined when a consumer attempts to make a credit card purchase in a store (on their own credit card). The downstream effect here is that the cardholder might try a different card or opt to pay with cash. In most cases, a declined card doesn’t stop the sale or exchange from taking place and is typically only a minor—if irritating—inconvenience for both parties.
But when the transaction takes place not in person but online, what was a minor inconvenience now holds the potential loss of a sale. For smaller or newer companies, too many false positives can be very detrimental when trying to grow a user base.
False positives can also be a serious problem for companies with few users but high transaction volume for the users they do have. A moderate false positive rate might not erroneously flag too many transactions, but it could still affect a significant portion of its user base.
Savvy companies can try to engineer around some of these effects by building a seamless experience that addresses potential false positives. In the case of an online transaction, developing a quick and automated way for a user to provide additional proof of identity or account ownership makes it much easier to resolve any mistakenly declined legitimate transactions. Alternatively, larger companies with efficient customer service teams can work to mitigate the negative impact these mistakes have on the user experience.
The latency of false negatives
Unlike false positives, whose effects are felt at the time of the transaction, false negatives often aren’t noticed until much later in the transaction process. When a fraudulent transaction is mistakenly allowed through, the transaction is completed as usual. This leaves the account owner unaware of the fraud until the unauthorized charge shows up on his account. The merchant, for its part, may remain unaware of the fraud until well after the transaction takes place and there is a chargeback or a reversal.
These types of mistakes will ultimately cost the company processing the business’s payments because it will be on the hook for the loss. An established processor, with a large bankroll, may be able to handle these losses without issue, but for smaller companies or businesses with low margins, these losses can quickly add up.
What’s more, too many of these types of mistakes can quickly erode trust in the payment platform on both sides of the transaction. Consumers will be less likely to use a platform if they are afraid it exposes them to unauthorized access of their funds. Even if the losses are covered, recouping lost funds can take time and energy, and consumers have no shortage of choices. Likewise, merchants may stop accepting that form of payment or may switch to a more reliable alternative that is less prone to these types of headaches since these issues may still reflect badly on the business in the eyes of their customers.
For an established company with a good reputation, this degradation may be most important. It can take years to build consumer trust, which can be rapidly torn down with a few missed fraudulent transactions.
Aggressive/passive models and model adjustments
The distinction between aggressive and passive models is pretty straightforward. A fraud model can be thought of as aggressive if it’s more likely to label a transaction as fraudulent, letting fewer fraudulent transactions slip through but being more likely to mistakenly stop a legitimate transaction. Conversely, a passive model lets more transactions through, reducing the chances of mistakenly stopping a legitimate transaction but increasing the chance of a fraudulent transaction slipping through. A company can employ a more aggressive or passive model depending on which types of mistakes it is better at handling or are less detrimental.
Adjusting a model’s “aggressiveness” depends on the type of model. For rules-based models, the individual rules dictate how aggressive or passive the model is. One method of making a rules-based model more aggressive is by adjusting the parameters in the rules.
Consider the rule “a transaction is fraudulent if it is at an infrequently visited gas station far from the card's billing address.” A rule that defines “far” as 25 miles is aggressive, given that people are quite likely to purchase gas 25 miles away from their billing address. Establishing “far” as 200 miles or farther, on the other hand, is more passive, since most people do not commonly fill up that far from home.
In addition, making a rule more elaborate or specific will make a rules-based model more passive: because super-specific rules apply to fewer transactions, the model will be less likely to label a transaction as fraudulent. Take the (hypothetical) rule “a transaction is fraudulent if it is at an infrequently visited gas station 200 miles from the card's billing address and occurs after a purchase of $30 or more at McDonald’s.” This rule only flags transactions that fulfill both the distance and the purchase sequence requirements, meaning that it is ultimately passive to most transactions.
It’s harder to define how these adjustments are made for algorithmic models, as changes are specific to the algorithm used, but we can think of model aggressiveness in terms of fraud scores. Algorithmic fraud models generate a “fraud score” for each transaction, with low scores corresponding to transactions that are likely legitimate and high scores to transactions that are probably fraudulent. Adjusting the score cutoff for when a transaction gets labeled as fraudulent dictates how aggressive or passive the model is. A more passive model only labels transactions with very high scores as fraudulent, whereas a more aggressive model might maintain a lower minimum score threshold for labeling a transaction as fraudulent.
Ultimately, a company must determine the potential downstream effects of both false positives and false negatives and adjust its model to minimize negative business outcomes. This is where large companies have the advantage—extra capital and resources can alleviate both types of mistakes—but they are also weighed down by the need to protect their existing customer base and reputation. Smaller companies are typically more agile and growth-focused, but they are also resource-restrained and in need of balancing seamless experience with trust-building for new users.
That’s where the art of choosing a fraud model, and making adjustments, comes in. As business goals evolve and customer feedback indicates how the company’s users respond to mistakes, so, too, should the model evolve.